ISTQB AI Testing Prep iOS and Android App
Elevate your ISTQB AI Testing skills with ISTQB AI Testing Prep!
Unlock the path to certification excellence with our dynamic app, expertly crafted to immerse you in one of the most advanced and interactive exam preparation experiences available today.
Dive into a world of comprehensive practice questions meticulously designed to cover all essential domains necessary for your ISTQB AI certification journey.
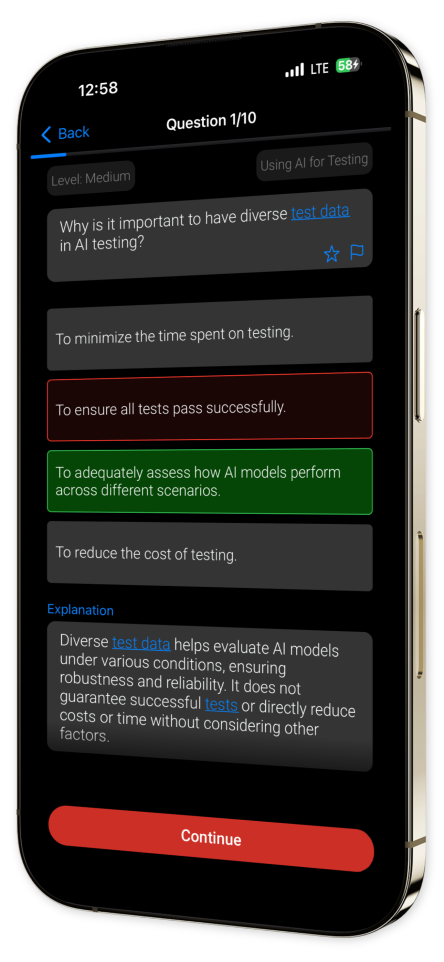
Each question is accompanied by an in-depth explanation, ensuring you don't just memorize — you master.
Key Features:
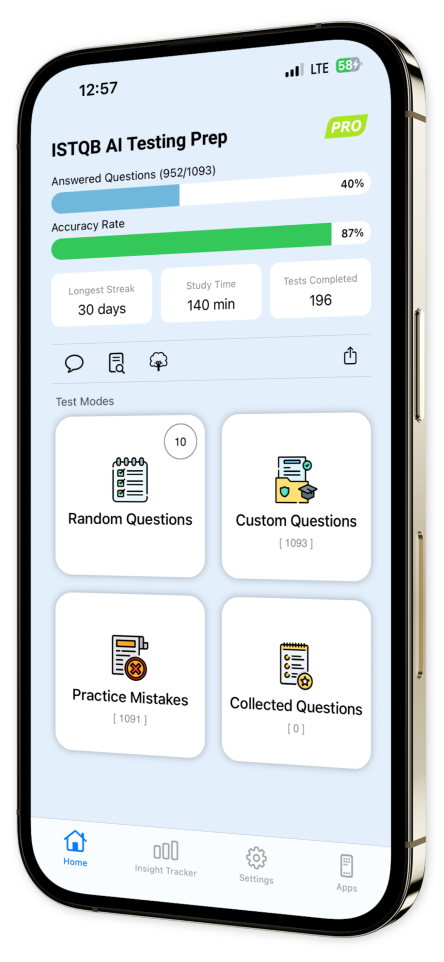
Extensive Question Bank: Plunge into an expansive collection of questions, methodically structured to cover all critical aspects of AI Testing for a thorough preparation journey.
In-Depth Explanations: Enhance your learning curve by diving into detailed rationales that accompany every question, reinforcing your understanding and retention of core concepts.
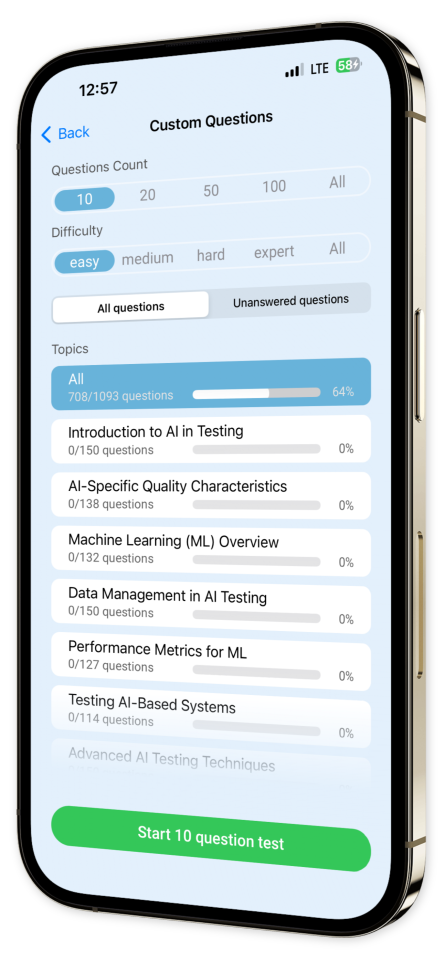
Customizable Quizzes: Tailor your learning experience by creating quizzes focused on specific topics and question types, allowing you to zero in on areas where you seek improvement.
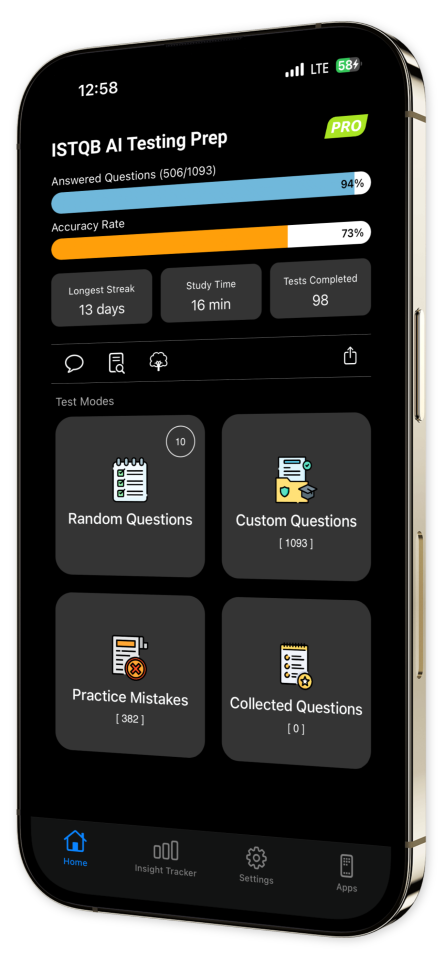
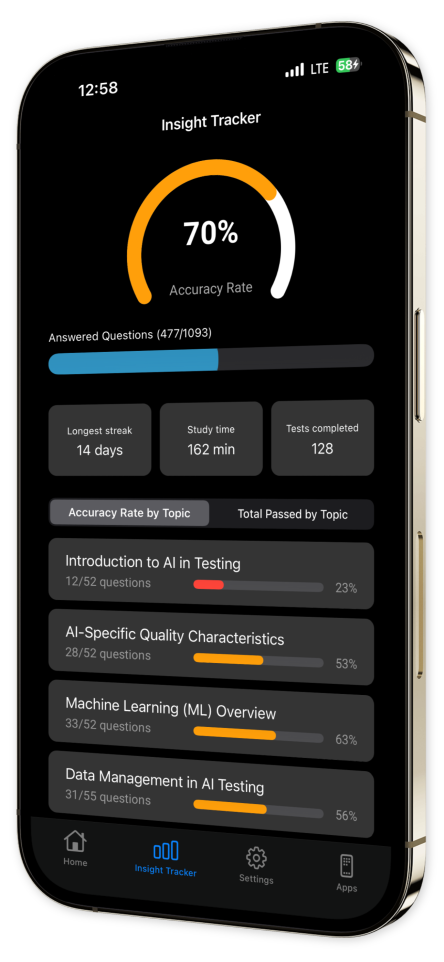
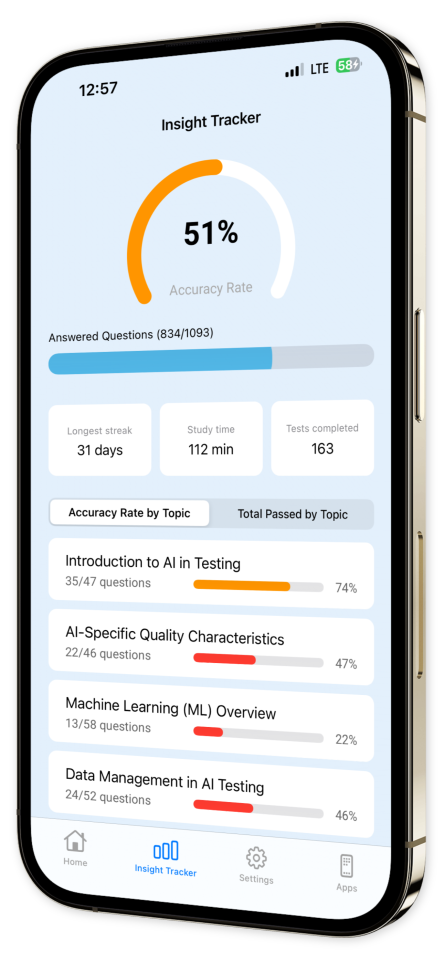
Progress Tracking: Watch your confidence grow as you track your progress comprehensively over time with our sophisticated and user-friendly progress tracking tools.
Offline Access: Break free from connectivity constraints by accessing your study materials anytime, anywhere, ensuring effective learning even on the move.
User-Friendly Interface: Navigate through your learning seamlessly with our intuitive design, keeping your mind focused and your app experience smooth and easy.
Download ISTQB AI Testing Prep today and embark on a groundbreaking journey to certification readiness. Master the material with a smarter approach and unlock your potential to become an AI-infused ISTQB-certified professional! As the world of AI evolves, so should you. Take the leap now, set yourself apart, and shine brighter in your professional development with ISTQB AI Testing Prep!


Content Overview
Explore a variety of topics covered in the app.
Example questions
Let's look at some sample questions
Which tool is specifically designed for hyperparameter optimization in machine learning models?
OptunaScikit-learnPandasOpenCV
Optuna is an open-source software framework specifically designed for hyperparameter optimization in machine learning models. It automates the search process to find optimal hyperparameters efficiently.
How can redundancy contribute to the reliability of AI systems?
By increasing the complexity of the systemBy providing backup components to take over in case of failureBy reducing the need for human oversightBy decreasing the cost of system maintenance
Redundancy involves having backup components that can take over if primary components fail, thus enhancing the reliability of AI systems.
What type of machine learning algorithm is used when the model learns from labeled data to make predictions?
Supervised LearningUnsupervised LearningReinforcement LearningSemi-supervised Learning
Supervised learning involves training a model on labeled data, where the input and the desired output are provided, allowing the model to learn the relationship between them.
How does feature selection benefit machine learning models?
It reduces overfitting by eliminating irrelevant or redundant featuresIt increases model complexity by adding more featuresIt enhances data privacy by masking sensitive informationIt speeds up data entry by automating feature creation
Feature selection benefits machine learning models by reducing overfitting through the elimination of irrelevant or redundant features, thereby improving model generalization and performance.
What is the primary goal of data labeling in AI model training?
To improve the computational power of the modelTo ensure that data is structured and organizedTo assign meaningful labels to raw data for supervised learningTo reduce the size of the dataset
Data labeling is crucial for supervised learning as it involves assigning meaningful labels to raw data, enabling the model to learn from examples.
What role does data normalization play in ensuring dataset quality for AI models?
It ensures consistent scaling of features for fair model trainingIt reduces the dataset size significantlyIt simplifies the model architectureIt enhances feature selection
Data normalization plays a critical role in ensuring dataset quality by ensuring consistent scaling of features, which is crucial for fair and effective model training, especially when features have different units or scales.
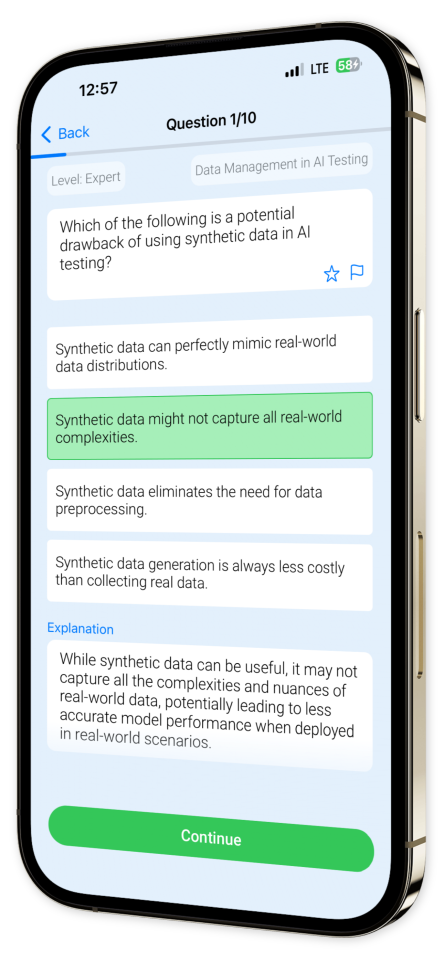
What is a primary advantage of using synthetic data in AI testing?
It eliminates the need for real-world data collection.It reduces the computational power required for testing.It guarantees 100% accuracy in AI model predictions.It allows for testing scenarios that are difficult to replicate with real data.
Synthetic data allows for the creation of diverse and rare scenarios which might be difficult or impossible to find in real-world datasets. This is particularly useful in testing edge cases and ensuring robust AI model performance.
How does mixup, a data augmentation technique, enhance the training dataset?
By interpolating between pairs of examples and their labelsBy duplicating examples with added Gaussian noiseBy randomly shuffling feature values within an exampleBy reversing the order of features in each example
Mixup enhances the training dataset by creating new examples through linear interpolation between pairs of examples and their corresponding labels, promoting smoother decision boundaries.
Which metric is best used when the cost of false positives is high?
RecallSpecificityPrecisionAccuracy
Precision is the best metric to use when the cost of false positives is high, as it measures the number of true positive results divided by the number of all positive results, including false positives.
In a binary classification model, if the precision is high but recall is low, what does this indicate about the model's predictions?
The model is good at identifying all positive instances.The model is good at identifying positive instances but misses many.The model is making many false positive predictions.The model is making many false negative predictions.
High precision with low recall indicates that the model is correctly identifying positive instances when it predicts them, but it is missing many actual positive instances, leading to a high number of false negatives.
Gallery